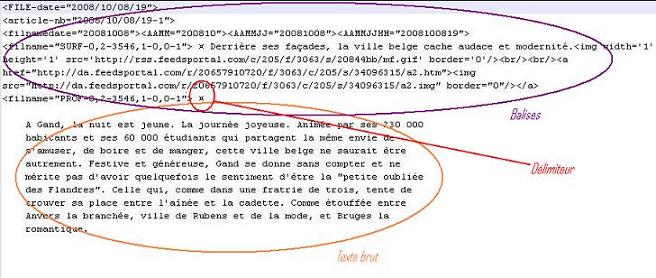
Pour parvenir au résultat ci-dessus, nous avons commencé par utiliser un script qui ne nous donnait pas de résultats satisfaisants. En effet, ce script utilisait une expression régulière qui ne nous permettait pas dextraire tous les contextes obtenus dans la balise <description> des fils RSS. Nous nobtenions que six mois sur douze de données textuelles. Cest pourquoi nous avons pris la décision dintégrer dans ce script la bibliothèque XML::RSS de Perl . Cette bibliothèque permet dextraire tout le contenu des balises <description> quelque soit la mise en forme des données dans le fichier XML.
Pour télécharger ce script, cliquez ICI
Cependant, en lançant ce programme pour la première fois, nous nous sommes heurtés à un problème de mal formation des fichiers XML. En effet, certains fichiers contenaient des liens vers des feuilles de styles XSL :
<?xml-stylesheet type='text/xsl' href='http://rss.feedsportal.com/xsl/fr/rss.xsl'?>
Comme ces feuilles de styles nétaient pas physiquement présentes dans nos dossiers, il a fallu supprimer les liens vers ces feuilles pour éviter les erreurs de mal formation qui empêchaient la bibliothèque de fonctionner. Pour supprimer ces liens gênants, nous avons créé un autre programme qui a nettoyé en amont les fichiers contenus dans larborescence. Pour télécharger ce script, cliquez ICI
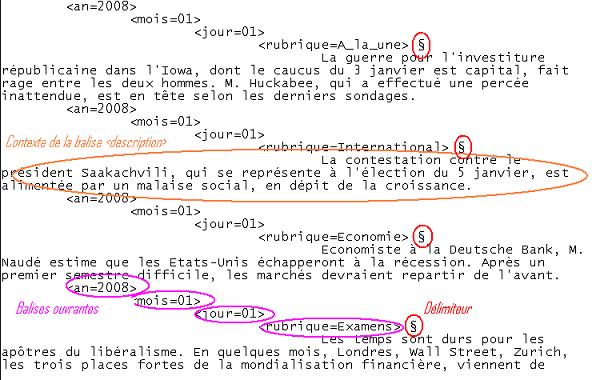
Ainsi, le premier script contenant la bibliothèque a pu tourner sur toute larborescence sans rencontrer dobstacle. Nous obtenions alors une sortie au format Lexico3. Cependant, il restait encore des problèmes de codage. On trouvait des entités html et des entités décimales comme par exemple : &#eacute; qui code le é ou ' qui code le . Il a donc fallu rajouter un bloc de nettoyage qui supprimait ces entités. Ainsi, nous avons créé un troisième script contenant uniquement ce bloc de nettoyage. Pour télécharger ce script, cliquez ICI
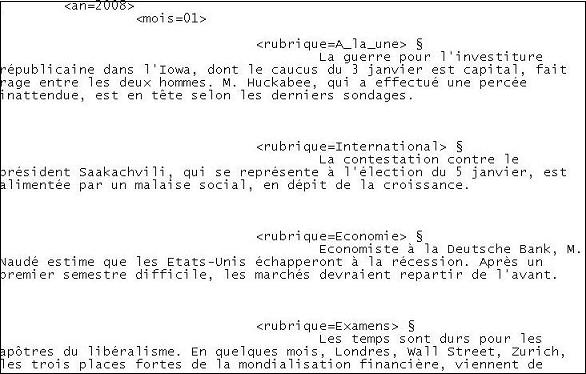
Nous avons alors obtenu une sortie totalement nettoyée.
On peut remarquer que nous navons pas extrait que les fils qui contenaient le mot crise mais également ceux contenant les mots ou les expressions régulières : subprimes, banque, bancaire, FMI, financ, récession, économi, monétaire, liquidité, croissance, bours, conjoncture, capital[^e], capitali, prix, marché, crédit, renfloue, inflation, taux, consomm, délocalis, immobilier. Nous avons choisi ces mots car ils apparaissaient dans le contexte du mot crise. On constate que certains mots sont tronqués, comme financ ce qui permet de récupérer plusieurs mots à la fois comme : finance, financer, financement. On voit aussi une expression régulière avec : capital[^e] qui permet dexclure le nom féminin capitale. Lajout de ces mots a permis dobtenir une sortie plus complète.