
Boite à Outils 1 : Automatisation du filtrage sur un arbre de fils
Objectif
Cette première boîte à outils avait deux objectifs :
(1) Créer un fichier de sortie xml pour chaque rubrique.
(2) Filtrer et nettoyer le corpus. On veut récupérer ici les contenus textuels des balises DESCRIPTION contenues dans la balise ITEM.
Pour ce faire, nous sommes parties d'un script PERL fourni par les professeurs que nous avons amélioré afin de créer les fichiers voulus. Nous avons ensuite intégrer à ce script un filtreur et un nettoyeur.
Squelette détaillé du programme fourni
téléchargeable ici : parcours-arborescence-fichiers.pl
#!/usr/bin/perl
<<DOC;
Votre Nom :
JANVIER 2005
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie un fichier structuré contenant sur chaque
ligne le nom du fichier et le résultat du filtrage :
<FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
DOC
#-----------------------------------------------------------
my $rep="$ARGV[0]"; # "$ARGV[0]" correspond au répertoire contenant les fichiers. Il a été indiqué dans la commande perl, juste après le nom du programme
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
my $DUMPFULL1="";
#----------------------------------------
my $output1="SORTIE.xml";
if (!open (FILEOUT,">$output1")) { die "Pb a l'ouverture du fichier $output1"}; # on ouvre notre fichier de sortie
#----------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#----------------------------------------
print FILEOUT "<?xml version=\"1.0\" encoding=\"iso-8859-1\" ?>\n"; # on y crée notre structure XML
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Votre nom</NOM>\n";
print FILEOUT "<FILTRAGE>".$DUMPFULL1."</FILTRAGE>\n"; # on y intègre ce qu'on a filtré
print FILEOUT "</PARCOURS>\n"; # on referme la structure
close(FILEOUT);
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n"; # on ouvre le répertoire courant
my @files = readdir(DIR); # on lit ce qu'il contient et on en fait une liste
closedir(DIR); # on referme le répertoire
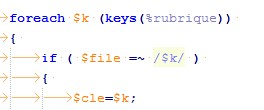
foreach my $file (@files) { # pour chaque contenu de la liste,
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) { # si c'est un répertoire,
&parcoursarborescencefichiers($file); #recurse! # on recommence
}
if (-f $file) { # si c'est un fichier
# TRAITEMENT à réaliser sur chaque fichier ### A NOUS DE JOUER
# Insérer ici votre code (le filtreur)
print $i++,"\n";
}
}
}
Traitement à réaliser :
Il va nous falloir :
- vérifier que c'est bien un fichier xml (puisqu'on ne traite que ceux-là et non leurs doubles .txt). Pour cela, rien de plus simple : un petit test if.
![]() Attention, on ouvre une parenthèse juste après et on ne la refermera qu'en fin de fichier!
Attention, on ouvre une parenthèse juste après et on ne la refermera qu'en fin de fichier!
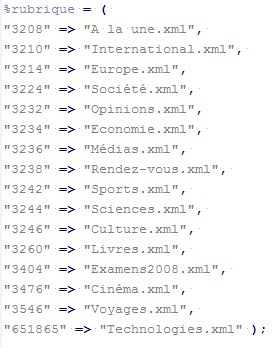
- vérifier à quelle rubrique il correspond et dirigé le filtrage vers la bonne sortie. Ici, il va falloir utiliser au préalable une table de hachage (tableau indexé). En effet, on observe qu'à chaque rubrique correspond un nombre qui l'identifie. Notre table de hachage nous permet donc d'associer ce nombre à un fichier de sortie que l'on a créé, contenant le nom_de_la_rubrique et l'extension xml. On pourra donc ensuite pour chaque clé, vérifier à laquelle correspond le fichier que l'on a ouvert et redirigé alors correctement notre filtrage vers sa valeur (qui est le fichier de sortie créé).
 |
 |
|
 |
- récupérer le contenu de la balise description. Pour cela, on utilise aussi une boucle if et une expression régulière. Ainsi, on va lire notre fichier d'entrée ligne par ligne, et si la ligne contient les balises <description>, alors on récupère le texte qui est entre. On a cependant été vite confronté à un petit problème. En effet, la balise description est également présente une fois en début de fichier dans la balise <channel>. Pour ne pas l'inclure dans nos résultats, on va donc insérer un compteur qui ne récupèrera la ligne que si le compteur est différent de 0 (ie : il a déjà rencontré la balise que l'on veut éviter).
- enfin, nous avons été confronté à des problèmes de codage notamment, d'où le nettoyeur. Nous en avons aussi profité pour enlever quelques phrases inutiles :
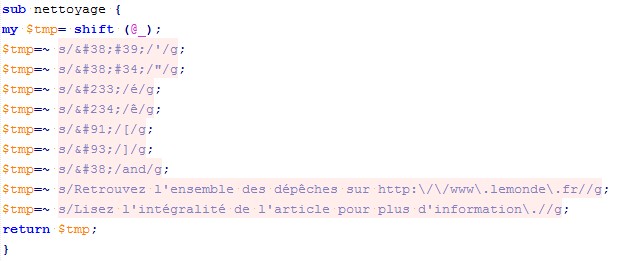
Le script complet peut être vu en cliquant ICI
Difficulté rencontrée
Notre principale difficulté ici a été d'intégrer les bases de Perl rapidement pour pouvoir comprendre et compléter le script initial. Nous ne connaissions pas du tout ce langage, et les premiers temps ont été un peu laborieux... Heureusement, nous avons pu prendre en option un cours d'Initiation à Perl, qui nous a permis de bien nous entraîner et de nous rassurer.