CORPUS
Cette partie présente les trois corpus avec lesquels nous avons travaillé. Après avoir mentionné leur provenance, nous décrivons les traitements préliminaires qui étaient destinés à la préparation de nos corpus pour une exploitation efficace. Une revue statistique détaillée présentant les corpus de point de vue quantitatif figure à la fin de cette section.
Table des matières
Corpus initiaux
Corpus Présidentielles
Le corpus Présidentielles-2007, constitué par Serge Fleury, ne prend en compte que les pages et fils RSS concernant les élections présidentielles 2007. Il est construit par concaténation des fichiers RSS archivés heure par heure et des articles qui leur sont associés.
Nous avons décidé de travailler uniquement avec les corpus corpus-fil-presidentiel-profond-2007.txt et
corpus-fil-presidentiel-profond-2006.txt contenant le contenu des articles du Monde sur les élections présidentielles.
Corpus Discours
Le corpus Discours, disponible sur le blog de Jean Véronis, est le résultat d’un travail réalisé de concert avec la contribution de Damon Mayaffre (CNRS, Nice), de Carine Duteil (CNRS, ATILF) et de Pascal Marchand (IUT, Toulouse). Il regroupe 230 discours, répertoriés en fonction des candidats officiellement en course à l’élection présidentielle. La période de récolte des données s’étend d’octobre 2006 au lendemain du premier tour.
Il faut préciser que pour les candidats sélectionnés au second tour, nous avons pris l’initiative de récupérer des données supplémentaires sur le blog de Jean Véronis; la collecte finale s’étend donc jusqu’au 6 mai 2007 : les derniers discours que nous avons récolté sont ceux prononcés à l’issue des résultats. Jean Véronis met en exergue l’inégalité de médiatisation de telles données.
En effet, si les données relatives aux candidats représentant des familles politiques bénéficiant d’un réseau de communication bien assis n’ont pas posé de problème de récupération, les discours des représentants d’organisations politiques dont l’équipe de communication était plus modeste ont été difficiles à récupérer, leurs équipes de campagne ne cherchant pas forcément toujours à les diffuser, au moins dans leur version numérique. C’est pourquoi une inégalité flagrante caractérise la proportion des discours collectés par candidat, ce que chacun peut constater en allant consulter le blog de Jean Véronis.
Nous avons décidé de travailler uniquement avec les discours des quatre candidats les plus importants : F. Bayrou (42 discours), J-M. Le Pen (27 discours), N. Sarkozy (57 discours) et S. Royal (42 discours). Nous avons également complété notre corpus avec les discours allant jusqu'au 6 mai 2007.
Corpus Débat
Le corpus Débat (transcription réalisée par Littera Stenotypie), récupéré par Pascal Marchand sur la version en ligne du journal Libération, est une transcription orthographique du débat opposant Ségolène Royal à Nicolas Sarkozy le 2 mai 2007, animé par Arlette Chabot et Patrick Poivre d’Arvor. La version qui nous en a été transmise par Serge Fleury et Pascal Marchand est formatée pour le traitement avec Lexico3, i.e. segmentée par des balises auteur spécifiées en attribut par le nom du locuteur, chabot, poivre, royal, sarkozy. Chaque tour de parole y est identifié par le marqueur §.
remonter
Traitements préliminaires des corpus
Avant de pouvoir extraire de l'information textuelle avec les outils que nous voulions utiliser (Lexico3, XML, Perl), il était nécessaire d'effectuer un certain nombre de modifications de nos corpus. Ceci avait pour but de minimiser l'influence des erreurs induites par des facteurs techniques tels que les incohérences dans l'encodage ou le balisage qui étaient malheureusement présentes dans les corpus initiaux. Cependant, nous avons été obligés de traiter ainsi uniquement les corpus Débat et Discours car il ne s'agissait pas encore d'un produit finalisé qui serait prêt, contrairement au corpus Présidentielles, à une exploitation lexicométrique et linguistique.
Encodage
Étant donné que nous voulons travailler avec des textes en langue française et également par le souci de compatibilité entre les différentes plate-formes utilisées (PC Windows XP, Cygwin, Mac OS X), nous avons décidé d'encoder nos corpus en ISO-Latin1 (ISO-8859-1). Les fichiers texte dont on disposait et qui étaient à la base constitués par la recopie du contenu provenant de l'internet (des pages générées en php pour les discours, un document pdf pour le débat), nécessitaient une modification pour être conformes avec cette norme.
Nous pouvions constater que nos corpus contenaient des caractères incompatibles avec la norme ISO grâce à la fonctionnalité de l'éditeur TextWrangler sous Mac OS X qui ne permet pas d'enregistrer un fichier texte dans un encodage donné si celui-ci contient des caractères qui n'appartiennent pas aux jeux de caractères de ce codage.
En pratique, il était nécessaire de remplacer les caractères propres à la norme Windows-1252 (Europe occidentale) par leurs équivalents en ISO Latin1. Il s'agissait des caractères suivants:
| Caractère Win1252 | code Win1252 | Caractère(s) ISO Latin1 | code ISO Latin1 |
|---|---|---|---|
| … (Ellipsis) | x85 | ... (point 3 fois) | x2E x2E x2E |
| œ (e dans l'o) | x9C | oe (o + e) | x6F x65 |
| ’ (Curved quotes) | x92 | ' (Apostrophe) | x27 |
| € (Euro) | x80 | Euro (E + u + r + o) | x45 x75 x72 x6F |
| – (Dash ponctuation) | x96 | - (Hyphen) | x2D |
Une image illustrant la façon de parcourir le fichier texte avec le programme 0xED afin d'identifier les caractères incompatibles avec la norme ISO Latin1 :

Sans avoir effectué ces modifications, nous risquions d'avoir des problèmes avec les logiciels utilisés. L'étiqueteur TreeTagger, par exemple, n'interprétait pas le signe ’(Curved quotes) comme un séparateur et il considérait les deux formes concaténées comme un seul token (par exemple cest, lhomme, na, etc. Ceci serait très gênant pendant l'exploitation.
remonter
Balisage Lexico3
Le corpus Débat, tel que nous l'avons obtenu, a été déjà prétraité pour pouvoir être exploité par Lexico3 : les tours de parole ont été marqués par des balises telles que <auteur="locuteur">, le début de chaque ligne a été marqué par le signe §. Malheureusement, ce balisage n'était pas adapté pour rendre compte de la vraie structuration du débat.
En effet, le balisage des tours de parole n'était pas complet car le document original utilisait deux façons différentes de marquer le locuteur et seulement une de ces méthodes a été prise en compte lors du balisage initial du corpus. Il fallait donc remplacer les suites § locuteur : par <auteur="locuteur"> afin d'unifier le marquage de cette information dans notre corpus. Ceci peut être fait assez rapidement avec la fonction chercher/remplacer d'un éditeur de texte. Nous avons donc remplacé les éléments suivants :
- § Ségolène Royal : 50 occurrences
- § Nicolas Sarkozy : 46 occurrences
- § Arlette Chabot : 3 occurrences
- § Patrick Poivre d'Arvor : 7 occurrences
Le signe § correspondait à la segmentation du débat en paragraphes. Cette segmentation a été introduite lors de la retranscription du débat en forme écrite. En général, un paragraphe correspondait à un tour de parole, mais dans certains cas, plusieurs paragraphes étaient présents au sein d'un tour de parole d'un locuteur. Garder cette information n'était pas trop pertinent car elle correspondait plutôt à la vision de celui qui a transcrit le débat qu'à la structuration réelle de la communication. Nous avons donc décidé de garder ce signe pour marquer uniquement les tours de parole pour Lexico3 et de segmenter notre texte en phrases (voir la section suivante) qui seront marquées par le signe $.
Le corpus Discours était fourni avec un balisage Lexico3 par auteur et par date (les balises <discours2007="auteur"> et <date="aaaammjj">) que nous avons gardées lors de l'ajout des discours plus récents (jusqu'au 6 mai). En plus, nous avons ajouté (avec une macro emacs) la balise <candidat-date="xx-aamm"> (contenant les initiales des candidats et l'année suivie du mois) qui était utile pour les exploitations longitudinales dans Lexico3.
Pour assurer la cohérence des données linguistiques, nous avons enlevé les titres de chaque discours (cependant nous les avons gardés dans la version XML, voir plus bas).
Un exemple d'un titre : François Bayrou, Discours au colloque UDF "Développement durable" (21/10/06).
Pour enlever ceci du corpus, nous avons utilisée une commande Unix, basée sur une spécificité du format des titres (la date parenthésée) qui ne figurait nulle part ailleurs :
$ grep -v '\(../../0.\)§' corpus_titre > corpus_sans_titre
La présence du signe § avait ici le même rôle comme dans le corpus Débat, nous avons alors décidé d'effectuer le même traitement (voir la section suivante).
remonter
Segmentation en phrases
Quelques uns des objectifs de notre recherche (calcul sur les longueurs des phrases, extraction des phrases contenant un certain motif, etc.) nécessitaient que l'on puisse travailler avec les phrases en tant qu'unités, extraites de nos corpus. Si nous considérons une phrase comme une suite de caractères terminée par un point, nous pouvons baser la segmentation sur ce critère. Par contre, nous ne devons pas oublier qu'un point dans le texte ne signifie pas forcément la fin de phrase.
Contrairement à ce que l'on pourrait penser, la segmentation en phrase est une tâche assez complexe. Nous avons décidé d'écrire un script perl qui traite les cas d'ambiguïté les plus fréquents : le point après une majuscule comme M. pour Monsieur et les trois points à la fin de la phrase. Ceci n'est bien sûr pas exhaustif (nous omettons par exemple le cas ou une phrase serait terminée par une majuscule), les résultats paraissent cependant assez satisfaisants.
Le script segmentPhrases.pl (à télécharger ici) prend en argument un fichier texte, le segmente et crée un fichier avec une phrase par ligne. Le script lit le fichier texte caractère par caractère et à chaque occurrence du caractère point, il décide en fonction des caractères suivants ou précédents s'il faut imprimer le saut de ligne.
Vous pouvez voir ici la boucle de lecture des caractères avec les critères qui servent à la décision (les expressions logiques dans les structures conditionnelles :
while($car[$i] ne "\0") #lecture du tableau de caractères du fichier
{
print Sortie $car[$i]; #imprime le caractère courant
if( ($car[$i] eq "\.") && #le caractère courant est un point et
($car[$i+1] ne "\.") && #le caractère suivant n'est pas un point et
($car[$i-1]=~ /[^A-Z]/) &&
($car[$i-1]=~ /[^0-9]/) && #le caractère précédent n'est pas majuscule et nombre
($car[$i+2]=~/[A-Z]/)) #le 2eme caractère suivant est une majuscule (début de phrase)
{
print Sortie "\n"; #si tout ça OK, imprime fin de ligne et saute l'espace
$i++;
}
if( ($car[$i] eq "\.") && #pour les trois points
($car[$i-1] eq "\.") &&
($car[$i-2] eq "\.") &&
($car[$i+2]=~/[A-Z]/))
{
print Sortie "\n"; #si tout ça OK, imprime fin de ligne et saute l'espace
$i++;
}
if((($car[$i] eq "!") || #pour gérer ! et ? (< > a cause des balises XML)
($car[$i] eq "\?")) &&
($car[$i+2]=~/[A-Z]/) &&
($car[$i-1] ne "<") &&
($car[$i+1] ne ">"))
{
print Sortie "\n"; #si tout ça OK, imprime fin de ligne et saute l'espace
$i++;
}
$i++; #la lecture du car suivant
}
Nous obtenons donc à la sortie un fichier avec le texte segmenté en phrases (une phrase par ligne). Après avoir enlevé les lignes vides (par exemple avec ce petit script), le fichier est prêt pour un balisage en XML - les balises Lexico3 originelles sont restées intactes après la segmentation et serviront de base pour ce balisage.
remonter
Balisage XML Débat
La balisage XML nous permet d'extraire de l'information de nos documents avec des transformations XSL. Ceci est particulièrement pratique notamment pour l'extraction des suites de mots spécifiques par des requêtes Xpath (extraction des patrons) qui est une alternative à des script d'extraction en Perl.
L'attribution d'une structure XML au corpus Débat pouvait être faite presque "manuellement". Il s'agissait de convertir (par la fonction rechercher/remplacer d'un éditeur de texte) les balises Lexico3 en format bien formé XML (c'est à dire par exemple <auteur="locuteur"> par <aut loc="locuteur">). Nous avons procédé de la même façon pour la génération des balises fermantes correspondantes (c'est à dire remplacer <aut loc="locuteur"> par </aut>\n<aut loc="locuteur">, etc.)
Le document XML bien formé que nous obtenons avec ces opérations en quelques minutes peut être finalement balisé au niveau des phrases - c'est à dire que chaque phrase du fichier segmenté (une phrase par ligne avec les balises séparées de l'autre texte par saut de ligne) peut être enfermée entre les balises <s></s>. Ceci peut être fait par un script (voir le script ajouteSent.pl ici) qui prend en argument le nom du fichier entrée, qui ajoute les balises <s></s> à chaque ligne à condition qu'elle ne contienne pas de chevron (ce qui voudrait dire qu'il s'agissait d'une balise XML), en sortie nous obtenons le fichier balisé.
La version XML du corpus Debat ainsi obtenue est structurée de la façon suivante :
<!ELEMENT aut ( s+ ) > <!ATTLIST aut loc ( chabot | poivre | royal | sarkozy ) #REQUIRED > <!ELEMENT debat ( aut+ ) > <!ELEMENT s ( #PCDATA ) >
Cette version du corpus Débat est disponible ici. Avec cette feuille de style nous pouvons extraire (à condition de changer le nom du locuteur dans la feuille) toutes les phrases prononcées par un locuteur donné.
Pour les besoins de l'extraction de l'information basée sur des critères grammaticaux, il était nécessaire d'annoter le fichier par un étiqueteur morphologique. Nous avons utilisé TreeTagger qui est simple à utiliser et les résultats sont satisfaisants. Nous pouvons annoter directement le fichier XML, car les lignes avec les balises ne sont pas étiquetées. Nous pouvons appeller TreeTagger par exemple de cette façon (à condition que le path de la commande soit valide) :
$ tree-tagger-french fichier-à-étiqueter fichier-sortie
Le fichier que nous obtenons doit être traité par un script de balisage (voir le script TT2xml.pl ici) qui structure l'information grammaticale issue du TreeTagger et l'intègre au document pour qu'on obtienne un document XML bien formé. La DTD de ce document est la suivante :
<!ELEMENT aut ( s+ ) > <!ATTLIST aut loc ( chabot | poivre | royal | sarkozy ) #REQUIRED > <!ELEMENT debat ( aut+ ) > <!ELEMENT s ( e+ ) > <!ELEMENT e (st, lm, tp) > <!ELEMENT st (#PCDATA) > <!ELEMENT lm (#PCDATA) > <!ELEMENT tp (#PCDATA) >
L'élément e contient les éléments st (string), lm (lemme) et tp (type - l'étiquette). Les noms des éléments ont été choisis courts pour diminuer au maximum le volume du document XML. Cela aide beaucoup (au niveau du temps) pendant le traitement du document.
remonter
Balisage XML Discours
Pour attribuer une structure XML au corpus Discours, nous avons procédé de la même façon comme dans le cas du débat à deux différences près - le titre de chaque discours a été inclus dans la structure XML par un script ajouteTitre.pl (à télécharger ici) qui parcourt le fichier ligne par ligne et ajoute les balises <titre></titre> à chaque ligne contenant l'expression régulière (.*\/0.) : il s'agit de l'indication de la date du discours - par exemple (21/10/06) - qui est unique dans tous le corpus.
Nous obtenons ainsi un fichier XML contenant tous les discours de nos quatre candidats. La DTD de ce document est la suivante:
<!ELEMENT cand ( disc+ ) > <!ATTLIST cand loc (royal | sarkozy | lepen | bayrou) #REQUIRED > <!ELEMENT disc ( titre, text ) > <!ATTLIST disc date NMTOKEN #REQUIRED > <!ELEMENT discours ( cand+ ) > <!ELEMENT p ( s+ ) > <!ELEMENT s ( #PCDATA ) > <!ELEMENT text ( p+ ) > <!ELEMENT titre ( #PCDATA ) >
L'élément p correspond à la division des discours par paragraphe dans leur version publiée sur le site de J. Veronis. La balise <p></p> a été ajoutée au corpus par un script ajoutePara.pl (à télécharger ici) avant la segmentation du fichier en phrases (donc à l'état où il contenait un paragraphe par ligne). Cette manipulation était optionnelle et elle n'aurait servi qu'au moment où nous aurions voulu utiliser la segmentation en paragraphes, ce qui n'était pas notre cas.
L'archive contenant le corpus Discours (avec les discours des quatre candidats choisis) est disponible ici.
Pour l'annotation avec TreeTagger, nous avons décidé d'annoter les discours de chaque candidat à part, sinon la taille du fichier annoté et structuré en XML serait trop importante pour une manipulation efficace. Nous avons extrait les discours de chaque candidat à l'aide de la feuille de style XSL ExtrCand2TXT.xsl (à télécharger ici) qui crée un fichier texte avec les discours (sans titres) du candidat spécifié dans la feuille de style.
Le fichier texte obtenu peut être ensuite annoté par TreeTagger et converti au format XML par un script Perl TT2xml2.pl (à télécharger ici) qui structure la sortie du TreeTagger de la même façon que dans le cas du corpus Débat (c'est à dire qu'il crée l'élément e qui contient les éléments st (string), lm (lemme) et tp (type - l'étiquette).
remonter
Caractéristiques des corpus
Calculs quantitatifs
Afin de caractériser nos corpus, nous nous sommes intéressés par des données quantitatives telles que, entre autres, le nombre moyen de mots ou de caractères alphanumériques dans une phrase et la longueur moyenne d'un mot en caractères. Nous supposons que ces informations peuvent donner un aperçu de certaines tendances dans les différentes sous-parties de nos corpus. Cependant, nous n'avons pas voulu essayer d'interpréter ces tendances, notre but étant uniquement de fournir des données qui pourraient aider une telle analyse.
Les outils que nous avions à notre disposition (Lexico3, commande Unix wc -lwc) ne proposent pas de faire ces calculs nous avons alors décidé d'écrire deux scripts Perl : CalcCars.pl (à télécharger ici) et StatsPhMot.pl (à télécharger ici). Les scripts sont destinés à lire uniquement du texte brut segmenté en phrases (une phrase par ligne).
Le script CalcCars.pl parcourt le fichier passé en argument et imprime un rapport avec les informations suivantes :
Nombre de caractères total Nombre de caractères alphanumériques Nombre de lignes
La boucle de lecture du fichier est la suivante :
while(!eof(FIC))
{
$car[$i] = getc(FIC); #création du tableau pour les caracteres
if($car[$i]=~ /[a-zA-Z0-0]/) #si le caractere lu est alphanumerique
{
$j++;
}
if($car[$i] eq "\n") #si le caractere lu est fin de ligne
{
$k++;
}
$i++; #tous les caracteres
}
La commande Unix wc -lc peut aussi bien faire cette tâche mais elle ne distingue pas entre les caractères alphanumériques et les autres.
Le script StatsPhMot.pl parcourt le fichier passé en argument et imprime un rapport avec les informations suivantes :
Nombre de phrases Nombre de lignes vides Longueur moyenne d'une phrase en caractères Phrase la plus longue en caractères Nombre moyen de mots dans une phrase Phrase la plus longue en mots Nombre de mots Longueur moyenne d'un mot Mot le plus long
La boucle de lecture du fichier est la suivante :
foreach $ligne() #LECTURE DU FICHIER LIGNE PAR LIGNE { @slova = (); #vider la liste de mots tampon $j = 0; #initialiser le compteur de mots dans la phrase if($ligne !~ /^$/) #si la ligne lue n'est pas vide { $ph[$i] = $ligne; #tableau de phrases chomp $ligne; #enlever le car de la fin de ligne $phlong[$i] = length($ligne); #stocker la longuer de phrases sans LF &Separate; #appel du subprog Separate qui remplace tous les separateurs @slova = split(/\s/,$ligne); #créer un tableau de mots à partir de la ligne foreach (@slova) #inserer les mots de la phrase dans la listemots (linéaire) { $mots[$k] = $_; $motslong[$k] = length($_); $k++; #nb de mots dans le fichier $j++; #nb de mots dans la phrase } $phnbmot[$i] = $j; #nb de mots de la phrase $i++; #compteur de phrases } else { $iV++; #compteur des lignes vides } }
Cette boucle structure les données dans la mémoire afin que l'on puisse extraire (par les calculs dans la seconde partie du script) les informations dont nous avons besoin. Nous considérons ici un mot comme une suite de caractères alphanumériques délimitée par des séparateurs définis dans le script)
L'ensemble des rapports peut être visualisé ici:
- Rapport_CalcCars_bayrou.txt
- Rapport_CalcCars_lepen.txt
- Rapport_CalcCars_pres.txt
- Rapport_CalcCars_royal.txt
- Rapport_CalcCars_royal_db.txt
- Rapport_CalcCars_sarkozy.txt
- Rapport_CalcCars_sarkozy_db.txt
- Rapport_StatsPhMot_bayrou.txt
- Rapport_StatsPhMot_lepen.txt
- Rapport_StatsPhMot_pres.txt
- Rapport_StatsPhMot_royal.txt
- Rapport_StatsPhMot_royal_db.txt
- Rapport_StatsPhMot_sarkozy.txt
- Rapport_StatsPhMot_sarkozy_db.txt
remonter
Graphiques
Cette partie présente les données obtenues par les calculs en forme de graphiques. Les calculs ont été effectués sur le partitionnement suivant :
- Corpus Présidentielles :
pres
- Corpus Débat :
sarkozy_dbroyal_db
- Corpus Discours :
bayrou: 42 discourslepen: 27 discourssarkozy: 57 discoursroyal: 42 discours
Les calculs ont été effectués sur les versions du corpus contenant uniquement le contenu textuel segmenté par phrases.
remonter
La taille des corpus
Le volume total de nos données - les trois corpus (Présidentielles, Débat et Discours) concaténés - contient au total 7 067 386 caractères alphanumériques et 1 621 718 mots.
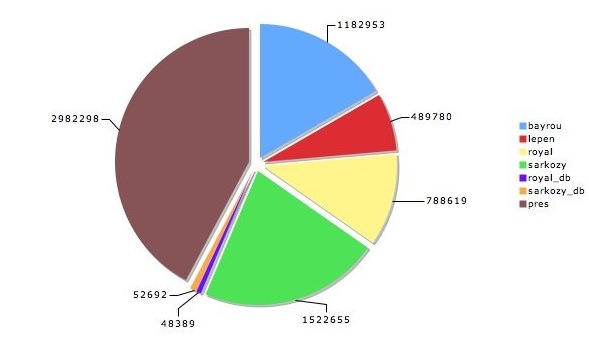
remonter
La longueur d'une phrase
En considérant les données obtenus, il ne faut pas oublier que la segmentation des énoncés en phrases (c'est-à-dire, à notre sens, en séquences de caractères terminées par un point sous certaines restrictions) peut être assez arbitraire. Il s'agit notamment de la segmentation des éléments coordonnés qui peuvent être rassemblés dans une seule phrase ou au contraire figurer en tant que phrases autonomes d'après des critères assez vagues.
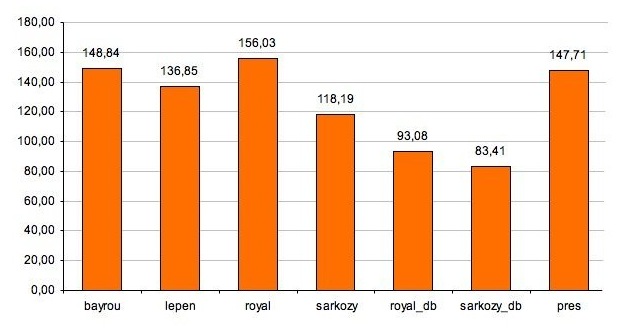
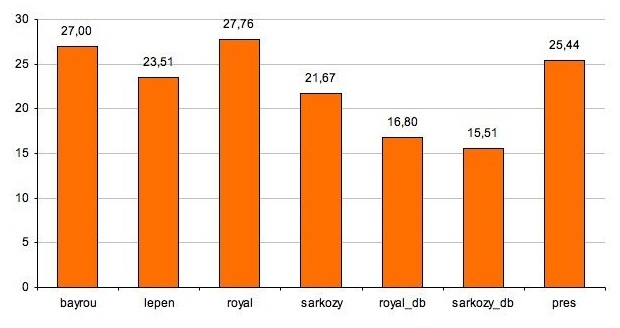
remonter
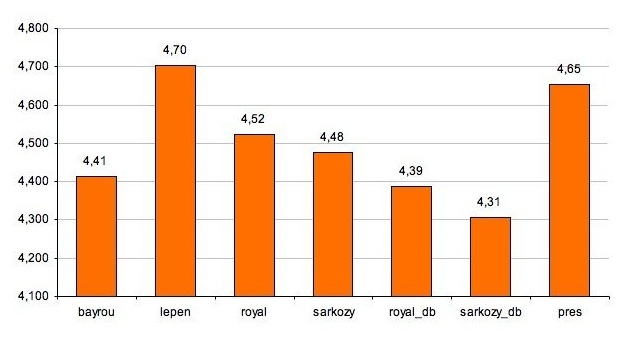
La longueur d'un mot
Les chiffres obtenus (entre 4,3 et 4,7 caractères) reflètent tout d'abord la haute fréquence des mots grammaticaux courts. Les trois mots les plus longs recensés dans nos corpus sont : intergouvernementale, professionnalisation, professionnalisantes. Malgré certaines tendances que nous pourrions dégager de nos données, il serait difficile de les mettre en rapport direct avec la complexité des énoncés.