Nous avons lancé une recherche avec le moteur Google en utilisant comme critère cinq usages dont les quatre premiers sont inventoriés par le TLF:
L'option recherche avancée du moteur Google nous a permis de faire un tri des pages pertinentes pour notre requête.
Pour chaque usage nous avons enregistré une cinquantaine d'adresses web.
Dans l'étape suivante, nous avons copié les adresses des sites retenus pour chaque sens du mot, et nous les avons
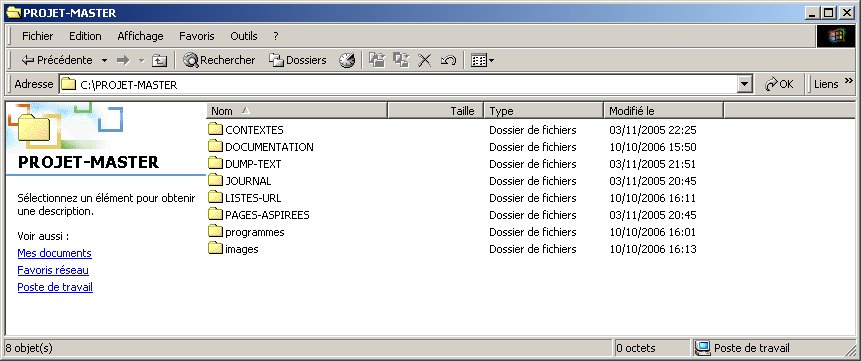
reparties dans cinq fichiers text distincts créés dans le répertoire LISTES-URL. L'arborescence qui
nous a été fournie au cours contient des repértoires spécifiques où seront directionnés les résultats
des différentes opérations executées par un script bash.
Ainsi, LISTES-URL contient les fichiers avec les adresses URL (5 fichiers
pour 5 usages différents); PAGES ASPIREES contient les pages html aspirées; DUMP-TEXT contient les pages dumpées
autrement dit le contenu texte des pages aspirées; CONTEXTES contient les fichiers textes qui stockent les résultats
de la commande egrep, dans notre cas, des contextes limités à 4 lignes du pattern "barrage"; PROGRAMMES est le répertoire qui
comprend plusieurs scripts. Nous avons généré 5 scripts et 5 sous-répertoires différents dans chacun des repértoires
que nous venons d'énumérer afin d'éviter qu'à chaque lancement du script, les résultats antérieurs ne soient écrasés.
Le script bash est l'élément-clé de l'arborescence qui nous a été fournie par les professeurs. Il permet l'automatisation des étapes du traitement des données. Pour une meilleure compréhension du mécanisme qui permet la génération des nos tableaux html, nous allons détailler les étapes de ce script:
echo "donne nom de fichier contenant les liens http"; #c'est la liste des pages wgettées read fic; #le programme connait le fichier de liens sous le nom $fic
echo "donne nom de fichier html où stocker ces liens"; #c'est le tableau de liens à créer
read tablo; #enregistre nom donné par utilisateur dans la variable $tablo
a) pour chaque ligne lue dans le fichier fic (chaque ligne correspond à une adresse web) le programme stocke
ce lien dans la variable nom. La commande wget permet d'aspirer le contenu du site qui correspond à l'adresse
et de le sauvegarder en local en tant que page html:
let i=1
for nom in `cat $fic` #$nom est la variable dans laquelle sera stocké chaque lien
{
wget -O ./PAGES-ASPIREES/usage-opposer/$i.html $nom
b) la commande lynx permet de recupérer le texte de l'url et de le stocker dans un fichier.
lynx -dump $nom > ./DUMP-TEXT/usage-opposer/$i.txt
c) egrep permet de récupérer toutes les lignes du texte récupéré dans l'étape b) qui contiennent le motif.
Les arguments A2 et B2 indiquent le nombre des lignes qui précèdent et qui suivent le motif.
egrep -i -A2 -B2 "opposer" ./DUMP-TEXT/usage-opposer/$i.txt > ./CONTEXTES/usage-opposer/$i-egrep.txt
d) le programme créé la ligne du tableau avec la balise tr. Chaque ligne contient 4 colonnes :
echo "<tr><td><a href=\"$nom\">$nom</a></td>
<td>
<a href= \"./PAGES-ASPIREES/usage-opposer/$i.html\">$i.html</a></td>
<td><a href= \"./DUMP-TEXT/usage-opposer/$i.txt\">$i.txt</a></td>
<td><a href= \"./CONTEXTES/usage-opposer/$i-egrep.txt\">$i-egrep.txt</a></td></tr>
>> $tablo;
{kind=link}