| Boîte à outils 5 | Retour |
|
Sommaire:
|
|---|
L’information mutuelle mesure l'attirance entre deux mots x et y, elle est donnée par la formule :
IM(x,y) = log(p(x,y) / p(x)p(y)).
p(x,y) probabilité d’apparition de la pair de mots (x,y).
p(x) probabilité d’apparition du mot x.
p(y) probabilité d’apparition du mot y.
Pour faire le calcul on divise le corpus en fenêtres.
Dans les fenêtres, on trouve sur chaque ligne un terme et sa catégorie séparés par _.
Pour séparer les fenêtres on utilise la balise <FinFenetre/>
a)Usage : perl fich_fenetres.pl fichier_texte_étiqueté fichier de sortie
b) Entrées : le texte etiqueté produit par Treetagger.c) Sortie : le fichier des fenêtres (le résultat).
Calculer la fréquence de chaque terme (occurrence) et générer un fichier xml qui
contient des balises de la forme :
< t c="occurrence" f="Valeur de la fréquence"/>
Usage : perl FaitIndexDeFenetres.pl fichier_des_fenetres> fichier de sortie
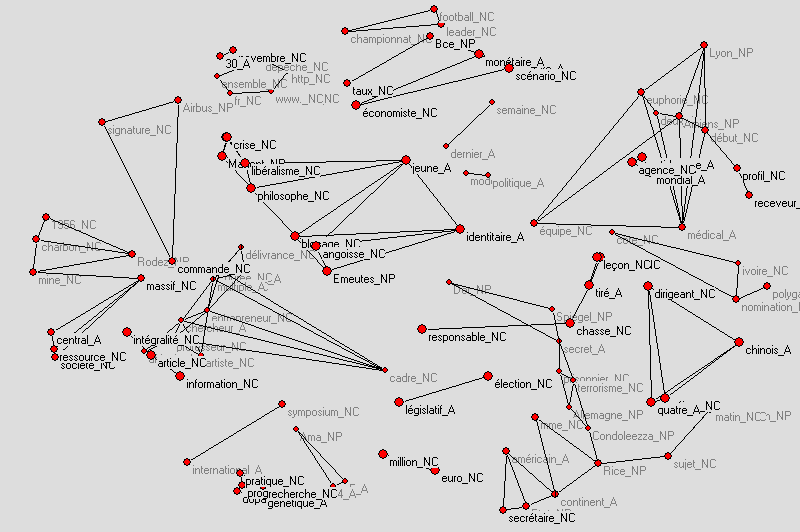
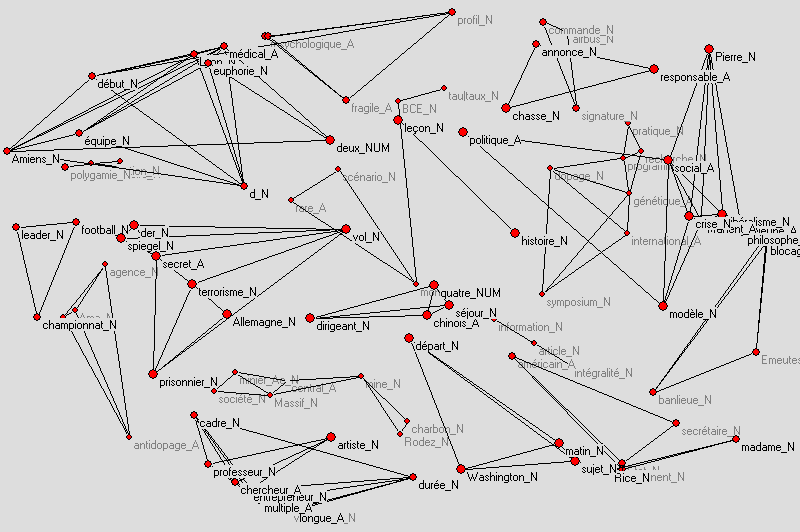
Le résultat pour Treetagger est disponible ici.
Dans cette partie on calcule les cooccurrences, au niveau des fenêtres, des termes dont les catégories
sont données en arguments.
Le fichier XML résultat contient des balises de la forme :
< t c1="occurrence" c2="occurrence2" f="co-fréquence" dm="distance moyenne"/>
La distance est le nombre de mots qui sépare les deux occurrences.
On utilise programme fourni : FaitCooccurrencesDansFenetre.pl
Usage : perl FaitCooccurrencesDansFenetre.pl fichier_des_fenetres catégories distance plafond cooccurrence plancher> fichier de sortie
Les categeries sont séparées par la barre verticale
À partir des fichiers obtenus à l’aide des programmes précédents, on calcule
l’information mutuelle en utilisant le programme fourni CooccurrencesDansFenetre2IM.pl
Usage : perl CooccurrencesDansFenetre2IM.pl fichier_index fichier_coocurences fréquence plancher> fichier de sortie
Le résultat pour Treetagger est disponible ici.Usage : perl IM2GraphML.pl fichier_xml_IM distance plafond IM plancher> fichier de sortie
Le résultat pour Treetagger est disponible ici.