| BoÓte ŗ outils 3 | Retour |
|
Sommaire:
|
|---|
…tant donnť des textes ťtiquetťs ŗ líaide díun outil comme Treetagger ou Cordial, le but est
de localiser puis díextraire des suites de termes dont les catťgories morphosyntaxiques sont
conformes ŗ des listes de patrons prťťtablies.
Pour atteindre cet objectif, on rťalise un script Perl qui prend en entrťe le texte ťtiquetť
et un fichier des patrons, puis produit en sortie un fichier contenant la liste des termes.
a)Usage : perl trouve_Treetagger.pl fichier_texte_ťtiquetť fichier_des_patrons_Treetagger > fichier_rťsultat
b) Entrťes : Exemple de fichier de patrons Treetagger:
Pour trouver toutes les suites (adjectif, nom) et ( nom, adjectif), on crťe un fichier des patrons contenant les deux lignes:
NOM ADJ
ADJ NOM
c) Sortie : Un fichier contenant les termes recherchťs.
d) Source :Le programme commentť est disponible ici .
Le code source au format texte est disponible ici.
Pour rťaliser líextraction des termes a partir des textes ťtiquetťs avec Cordial, le programme
prťcŤdent a ťtť lťgŤrement modifiť.
a)Usage : perl trouve_Cordial.pl fichier_texte_ťtiquetť fichier_des_patrons_Cordial > fichier_rťsultat
b) Entrťes : Exemple de fichier de patrons Cordial:
Pour trouver toutes les suites (adjectif, nom) et ( nom, adjectif), on crťe un fichier des patrons contenant les deux lignes:
NC[A-Z]+ ADJ[A-Z]+
ADJ[A-Z]+ NC[A-Z]+
Líexpression rťguliŤre [A-Z]+ est utilisťe pour prendre en compte tous les types de noms ou
adjectifs. Par exemple, pour les noms: NCFS, NCFP, NCSIG Öetc.
c) Sortie : Un fichier contenant les termes recherchťs.
d) Source :le programme commentť est disponible ici (les ligne modifiťes sont en vert).
Le code source au format texte est disponible ici.
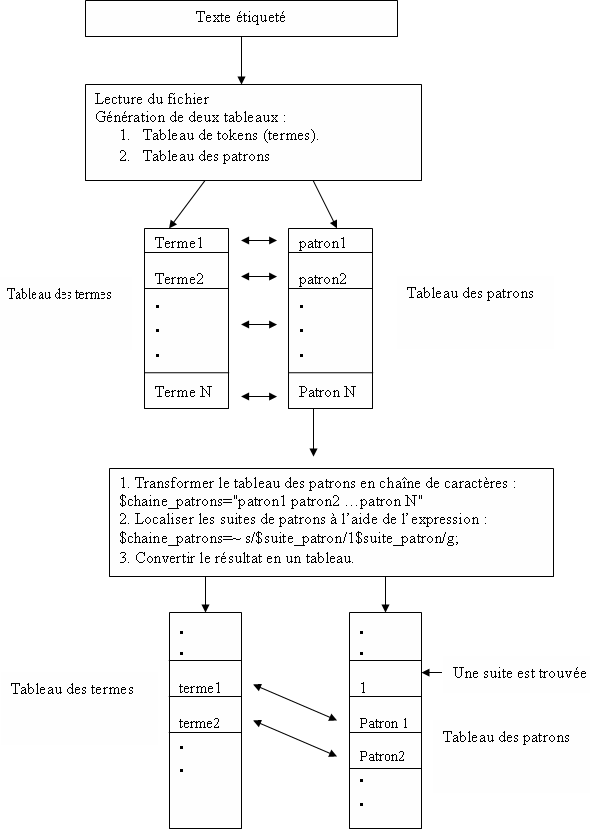
On extrait les termes et leurs catťgories ŗ partir du texte ťtiquetť, on les range dans deux
tableaux diffťrents, puis on transforme le tableau des patrons en une chaÓne de caractŤres
(la fonction perl ę join Ľ), puis ŗ líaide díune expression rťguliŤre on dťlimite avec la chaÓne "1"
toutes les suites de patrons recherchťes. Pour extraire les termes, il suffit díaccťder ŗ la position
correspondante dans le tableau des termes.
Localiser toutes les suites (adjectif, nom) et ( nom, adjectif), donc le fichier des patrons contient
les deux lignes:
ADJ NOM
NOM ADJ.
Le programme a ťtť modifiť pour produire un rťsultat au format html.
Localiser toutes les suites (dťterminant, nom) et ( prťposition ,nom), donc le fichier des patrons contient
les deux lignes:
DET[:a-zA-Z]* NOM
PRP[:a-zA-z]* NOM .
Le rťsultat au format html.
Localiser toutes les suites (adjectif, nom) et ( nom, adjectif), donc le fichier des patrons contient
les deux lignes:
ADJ[A-Z]+ NC[A-Z]+
NC[A-Z]+ ADJ[A-Z]+.
Le programme a ťtť modifiť pour produire un rťsultat au format html.
Localiser toutes les suites (dťterminant, nom) et ( prťposition ,nom), donc le fichier des patrons contient
les deux lignes:
DET[A-Z]+ NC[A-Z]+
PREP NC[A-Z]+
.
Le rťsultat au format html.
Localiser toutes les suites (dťterminant, nom,verbe) et ( prťposition , nom, verbe), donc le fichier des patrons contient
les deux lignes:
DET[A-Z]+ NC[A-Z]+ V[A-Z]+
PREP NC[A-Z]+ V[A-Z]+
Le rťsultat au format html.