le coprus du travail est fourni sous forme d'un
CDROM qui contient d'abord un sommaire des differents de ce que
comporte de CD, et qui sont:
1. Le corpus "Fils de la presse"
2. Le corpus "Fils de Presse + Articles complets associés au format
Lexico3"
3. en plus des outils necessaires pour la realisation du projet.
1. le corpus "fils de la presse" contients des fichiers contenants des fils de presse du journal " le monde ". qui couvrent la periode allant du 19/11/2005 au 23/02/2006. on retrouve ca donc sous la forme d'un tableau d'index qui contient deux colonnes. dans la premiere on y retrouve la date et l'heure d'emission ou de production, et dans l'autre colonne on y trouve des liens vers les "nuages" des mots au format HTML.
2. dans le deuxième corpus de son nom "Fils de Presse + Articles complets associés au format Lexico3" contient des archives des Fils de Presse (Le Monde) et les contenus textuels au format Lexico3 (fil + article), qui couvrent la periode allant du 17/01/2006 au 23/02/2006. le sinformations sont presentées ici egalement sous forme d'un tableau d'index qui est contient deux colonnes egalement; dans la première on y trouvent des informations relatives à la date et l'jeure d'emission. dans la seconde colonne on y trouvent des liens vers les "fil et nuage" sous forme de liens hypertexte HTML.
3. dans cette partie on y retrouve les differents outils necessaires à la réalisation du projet.
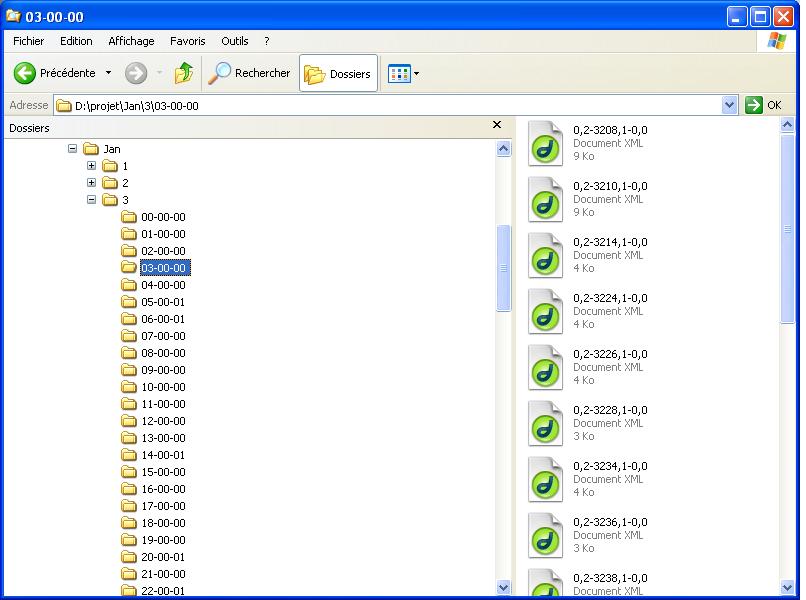
Pour ma partie, j'ai travaillé sur le répertoire 2006 du "corpus Fils de Presse" . le repertoire est formé de trois sous repertoires qui correspondent à trois mois; janvier, fevrier, et mars. le mois de janvier comprend a son tour 31 sous repertoires qui debouchent chaqu'un sur 23 sous repertoire qui contienent chaqu'un a leurs tour les fichier XML à traiter. Même organisation pour le les deux autres mois avec la différence que le mois de feverier comporte 28 sous ficchier, et le mois de mars 8 sous fichier.
Exemple avec Janvier:
Notre tâche consistait à "automatiser" le traitement "étiquetage et préparation des graphes", sur le corpus "2006" explicité en haut. il s'agit d'une chaine de traitement, qui consiste; en le filtrage, étiquetage, extraction morphologique, conception de fichiers au format de GRAPHML, et enfin la construction des graphes Pajek correspondants.
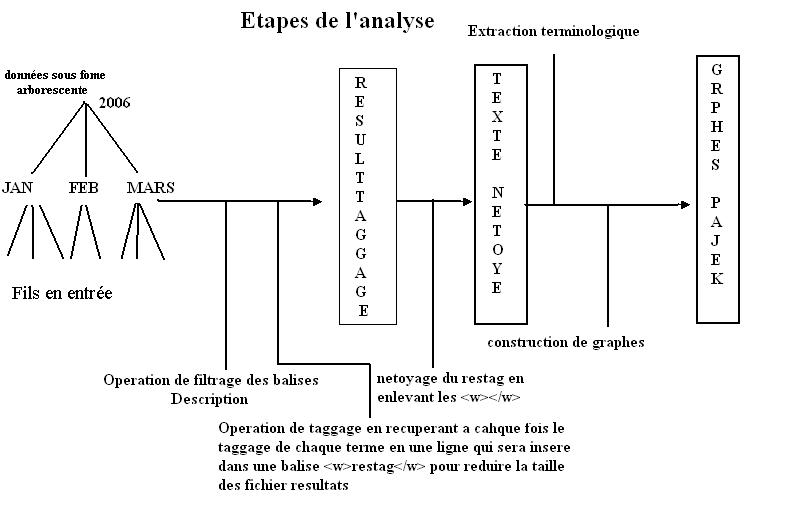
La première étape consistait donc a filtrer et extraire les balises <discription>, et pour se faire on a fait appel au programme d'extraction et parcours utilisé avec les boites à outils. Avec néanmoins une petite modification qui consiste a traiter juste les fichiers a extention XML, sachant qu'il ya des fichiers HTML dans les répertoires. un filtrage de fichiers qui s'effectue grâce à un petit test de cette forme:
if (-f $file) {
if (($file=~/AFP-stories\.xml/) || ($file=~/0,2-.*\.xml/)) {
On a effectué donc, le filtrage sur chaque fichier a part, de maniere à permettre une bonne visualisation des résultats ( limitation de temps et d'espace ), on a eu donc 31 fichier pour janvier, 28 pour fevrier, et 8 pour mars. a ce niveau là tout fonctionnait normalement et le vitesse d'exécution était vraiment appréciable.
vient après la partie de taggage, et c'est la partie la plus longue. qui nous crée nombre de problèmes a cause du volume des fichiers resultats et le temps vraiment très long que prenait le traitement de chaque fichier, un temps qui variait effectivement entre 3 heures, et 4h des fois pour un seul ficher. Et ce malgré la modification qu'on a apporté au programme de Taggage pour faire en sorte qu'il ne récupère qu'une seule ligne a chaque fois, et qui contiendrais ( la categorie , la forme, et le lemme ). dans une balise de cette forme :
<w> CAT FORME LEMME </w>
ce qui a fait diminué d'une manière appréciable la taille des fichiers résultats. Mais cette modification allait nous causer des problèmes un peu plus loin au niveau de la l'extraction terminologique à l'aide de patrons morphosyntaxiques. En effet quand on exécutait le programme on avait à la fin comme résultat, le fichier "TRACE" rempli, très bien rempli même, mais d'autre part le fichier texte résultat qui devait contenir les couples morphosyntaxiques extraits, restait inexplicablement vide. Mais grace à l'aide précieuse de notre cher enseignant et les modifications qu'il a apporté sur le programme on a dépassé ca. des modification qui consistaient d'abord a faire en sorte que le programme dépasse le fait qu' il n'y a pas de catégories SEN et/ou PUN dans notre fichier étiqueté ce qui posait probleme au programme lors de l'execution. L'autre modification consistait a anihiler la formation et la constitution du fichier "TRACE" qui etait d'une très grande taille, et ralentissait encore plus l'exécution du programme.
Il faut signaler qu'avant d'arriver a ce niveau ( extraction terminologique ), on a nettoyé les fichiers résultats du Taggage, et ce en supprimant les balises
<w> </w> de sorte qu'on obtienne en sortie un fichier texte organisé ligne par ligne.chose qu'on obtient grace à l'expression de retour chariot "\n". voilà le filtre utilisé:
#!/usr/bin/perl
if (!open (FILEOUT,">>filtre.txt")) { die "Pb"};
while ($ligne = <>){
if ($ligne=~/<w>(.*)<\/w>/) {
print FILEOUT "$1\n";
}
}
Revenant donc maintenant à l'extraction terminologique. En effet et faute de la dimension des fichiers a traiter, et rythme d'exécution très long. on a dû travailler avec des échantillons, car c'était impossible de faire le traitement sur les fichiers dans leurs intégralité. Pas avec ce programme de toute facon qui une fois que la taille du fichier dépassait un certain seuil, se metait a tourné sans arrêt. donc on a extrait 8000 lignes en moyenne de chaque fichier pour constituer chaque fois un fichier echantillon correspondant au fichier principal ( entier ).
Il faut signaler cependant que les résultats qu'on a eu ne correspondaientt vraiment pas des fois au catégories entrées dans le fichier patron.On a utilisé pour l'illustration des patrons: "NOM NOM" et " NOM ADJ", pour avoir des resultats appréciables même avec des fichiers échantillons (non volumuneux), sachant que ces couples étaient bien présents fréquement dans les fichiers. Mais ca n'as pas donné grand chose et on a pas eu les résultats vraiment escomptés et les fichiers contenant les patron extraits (résultats), étaient vraiment restraints. Résultats que vous l'imaginez bien nous donne des graphe également réduits.