
La chaîne des traitements :
Le point de départ :Des arborescences de dossiers dans lesquels sont stockés des fils RSS le Monde et AFP.
Les traitements à réaliser :
Effectuer sur les données des deux corpus les mêmes opérations définies dans les déférentes boîtes à outils.
Le schéma suivant résume ces opérations :
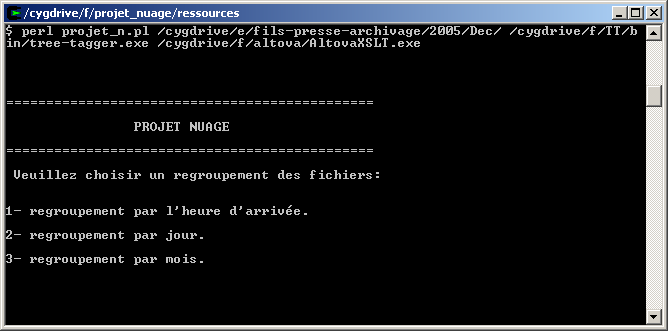
Usage: perl projet_n.pl nom du répertoire chemin d'accées à Treetagger chemin d'acces à AltovaXSLT
Entrée: nom du répertoire racine de l’arborescence.
Sortie:
Une arborescence de répertoires de racine corpus_res qui regroupe :
1-Des fichiers contenant les textes des balises description.
2- Des fichiers contenant ces textes étiquetés avec Treetagger.
3- Des fichiers contenant les suite des termes correspondants aux patrons
(NOM, ADJ) et (ADJ, NOM).
4. Des fichiers au format Graphml et Pajek.
Parcourir l’arborescence des répertoires en entrée à l’aide du programme de parcours de la boîte à outils 1.
À chaque passage par un dossier, si le niveau du dossier est supérieur au niveau choisi au lancement
du programme, créer un autre dossier portant le même nom dans l’arborescence résultat.
Extraire le contenu de balises description de chaque fil RSS, étiqueter le résultat avec Treetagger, puis à l’aide de la commande « system » de Perl, on appel tous les programmes déjà réalisés pour les boîtes à outils.
Le regroupement des résultats se fait à l’aide de la procédure « regrouper », le niveau d’un dossier est calculé grâce à la procédure « niveau ».
Pour générer les graphes de BO4 et de l’information mutuelle, on utilise la procédure gengraphe
Le schéma suivant explique le fonctionnement du programme :

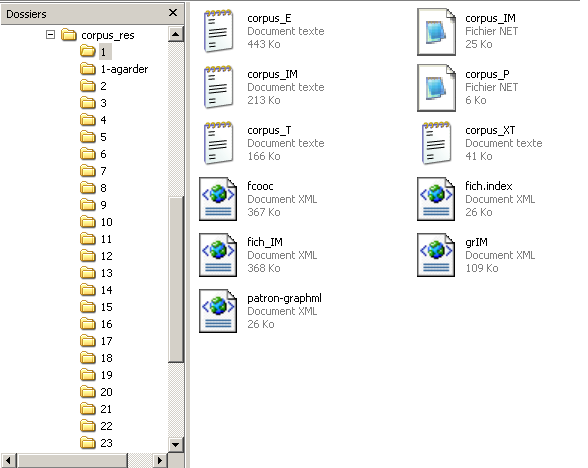
corpus_T : le texte avec un mot par ligne.
corpus_E : le texte étiqueté.
corpus_XT : le suites {nom, adjectif} et {adjectif, nom}.
corpus_IM : le fichiers des fenêtres pour l’information mutuelle.
corpus_IM.net : le fichier Pajek pour l’information mutuelle.
corpus_P.net : graphe des termes de la boîte à outils 4.
patron-graphml.xml: le fichier graphml de la boîte à outils 4.
Les autre fichiers xml sont utilisés pour le calcul de l’information mutuelle.
1-Le programme nécessite des heures d’exécution pour traiter complètement le corpus.
2- Pour générer les graphes Pajek (corpus_IM.net), il était nécessaire de changer
l’attribut encodage du graphe XML pour pouvoir le traiter avec AltovaXSLT .(le supprimer ou utiliser CP1252).
3- Les étiquettes traitées sont {nom, adjectif, abréviations} et les paramètres vus en cours
pour le calcul de l’information mutuelle sont utilisés dans l’exemple précèdent.