B. Habert
Projet Communautés
Cours 7
Le travail sur les dépendances syntaxiques majeures du mot
étudié donne une premier idée de ses emplois. Mais
la répartition en emplois se fait quand même à
partir de l'intuition que l'on a déjà a priori sur le mot
: on risque de ne pas se laisser surprendre, de ne pas voir des emplois
auxquels on ne s'attend pas. L'examen des segments
répétés et des concordances sous Lexico ne change
pas fondamentalement la situation.
On va recourir à DTM développé par Ludovic Lebart
pour regrouper les phrases contenant le mot examiné sans a
priori.
Le logiciel DTM est déchargeable sur le site www.lebart.org
Prendre la version en un seul morceau qui peut être
installée n'importe où sur l'ordinateur (tandis que la
version en 2 morceaux doit obligatoirement être dans un
répertoire DTM à la racine de C:).
Le mieux est de placer dans un répertoire DTM ainsi que le
fichier contenant les phrases avec le mot examiné (dans
Données sur les noms de Romanseval / Texte lemmatisé
pour DTM). Décompresser le fichier correspondant au mot
cherché. Pour barrage,
on obtient par exemple :
d683121p2s0 # le accalmie
permettre de récupérer de autre trace de fioul en mer ,
au moyen de flottant tracter par de le bateau , dans le pertuis breton
, séparer le île de le côte de le Marais Poitevin.le
sud de le estuaire de le Loire et le Vendée atteindre
également à nouveau par de le galette de fioul ce week -
end .
d683199p10s4 # un village
destiner à noyer sous le eau de un .
d683268p4s18 # de le
chiffre difficile à vérifier : de le policier interdire
à quiconque de se rendre dans le région .
d683320p4s6 # le haut
technologie de leur artisanat le placer sur un podium à le pied
duquel le public avoir pleinement le droit de venir se agenouiller en
rêver à de le jours meilleur , celui , sans doute , qui
lui permettre de oser franchir ce magnétique qui séparer
encore le convenablement bon de le invinciblement confidentiel .
...
Le format est le suivant : le "nom de la phrase" (d<n° de
document>p<n° de paragraphe>s<n° de phrase>), un
# entre espaces et le texte de la phrase lemmatisée, dont le mot
pivot (ici barrage) a
été enlevé pour ne pas rapprocher artificiellement
les phrases.
Une fois DTM lancé, on clique sur Data capture, puis Open.
L'écran ressemble à :
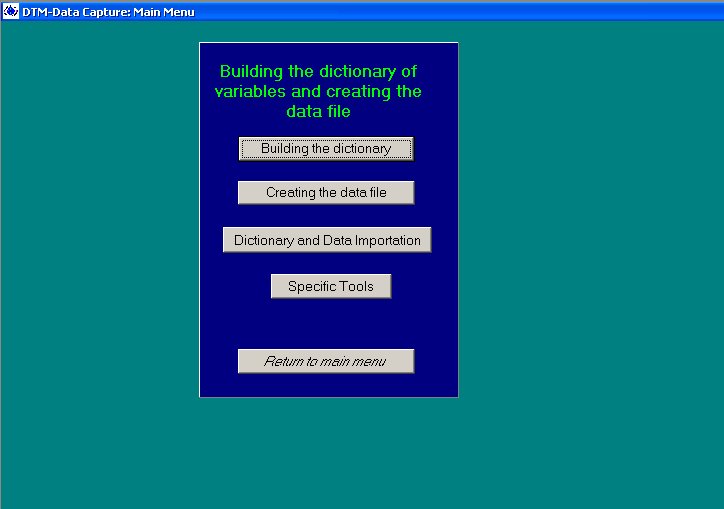
Il faut choisir Dictionary and Data Importation.
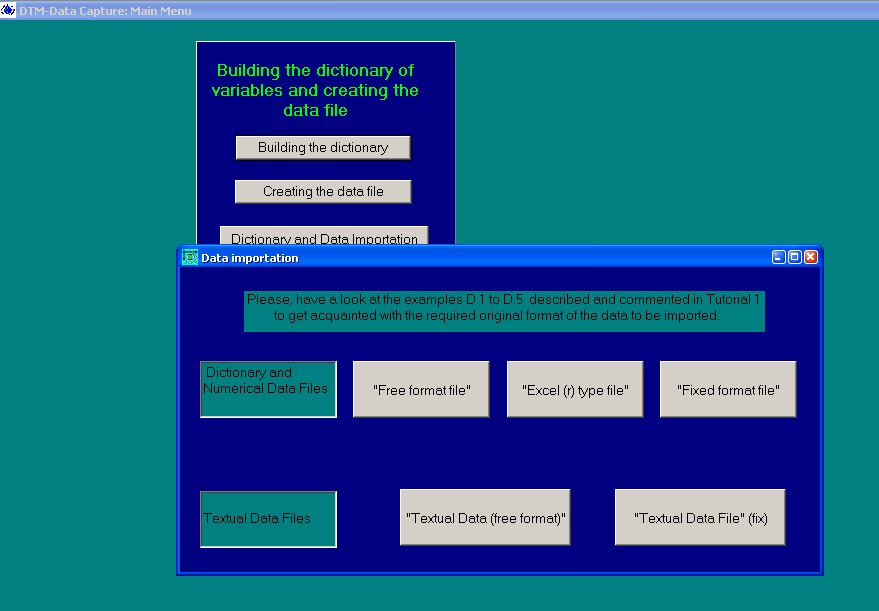
Il faut choisir Textual Data (free format).
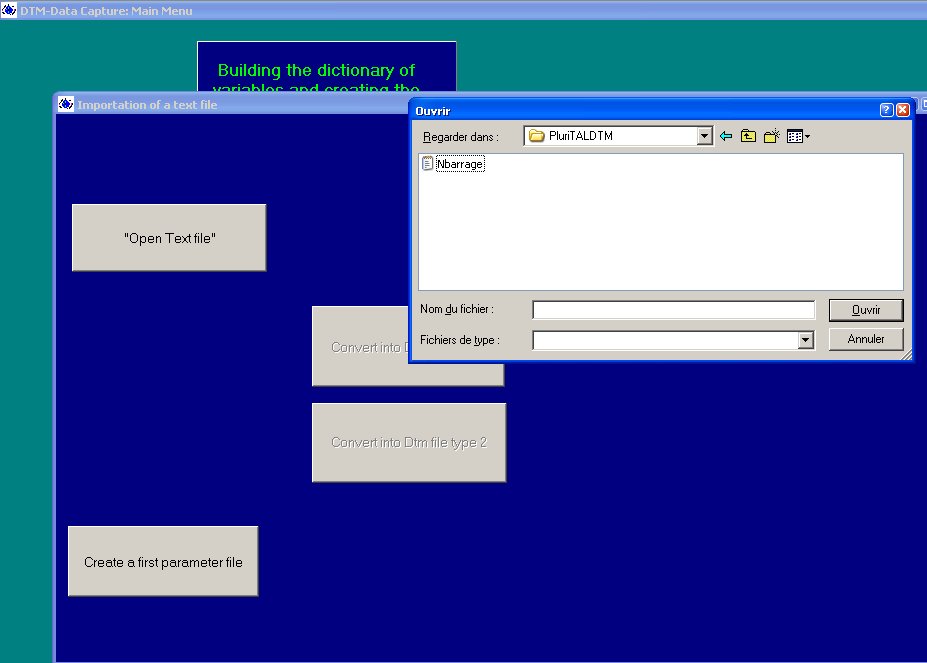
Une fenêtre de choix permet de sélectionner le fichier des
phrases du mot (ici Nbarrage.txt pour barrage).

Choisir Convert into Dtm file type 2
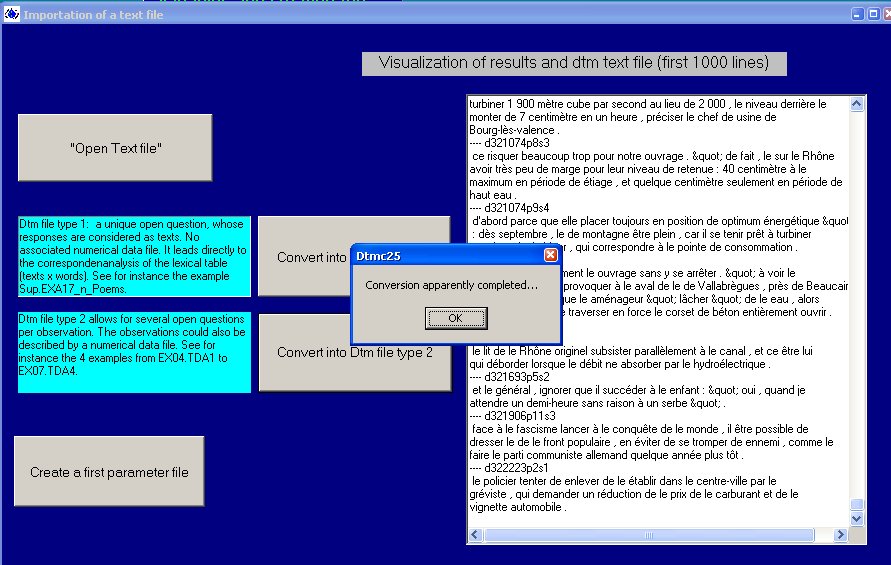
Une fenêtre apparaît sur la droite où défile
le texte au format interne de DTM.
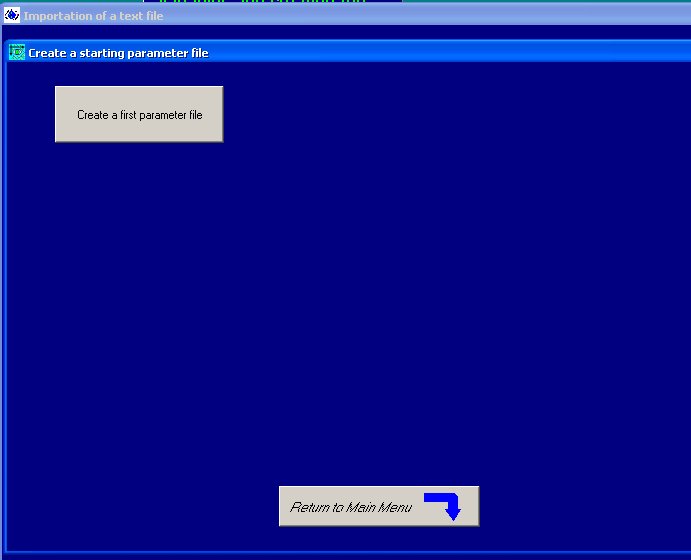
Après avoir accepté un certain nombre de fenêtres
de contrôle, qui attendent OK, on se trouve devant l'écran
supra. On clique sur Create a first parameter file.
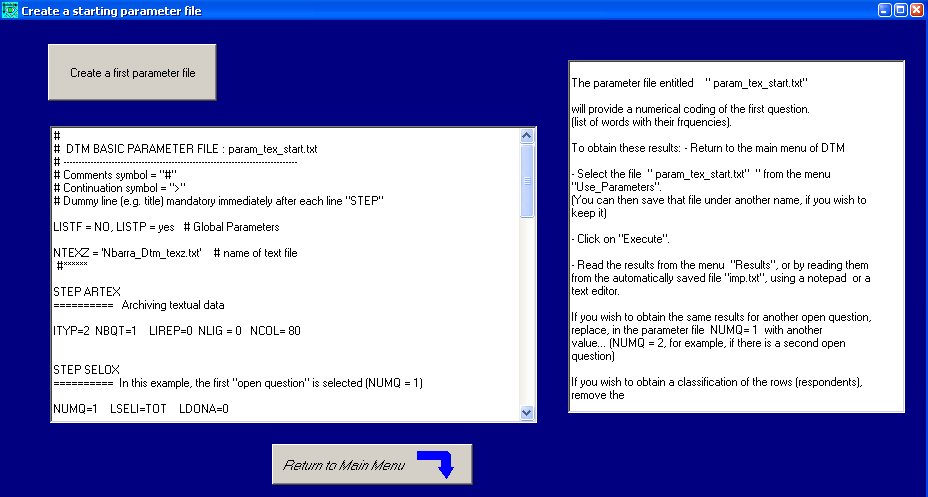
En cliquant sur Create a first parameter file, on voit défiler
un fichier de paramètres dans une fenêtre et on revient au
menu principal (Return to Main Menu).

En cliquant sur Use parameters, puis sur Open existing parameter files,
on peut ouvrir, dans le répertoire de travail le fichier de
paramètres crée : param_tex_start.txt.
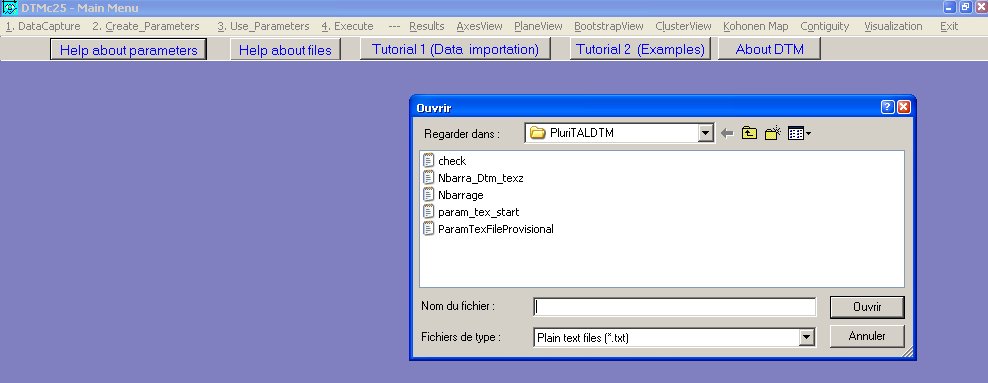
Ce fichier s'ouvre dans un éditeur sommaire :

La première opération consiste à enlever le STOP
(sans quoi DTM ne fait qu'une partie des opérations).

Une fois le STOP enlevé, aller en fin de fichier et
régler le nombre de classes voulu à l'issue du clustering
:

Ici il est de 25, ce qui rend les résultats peu utilisables. On
choisit la valeur souhaitée (ici 3) :

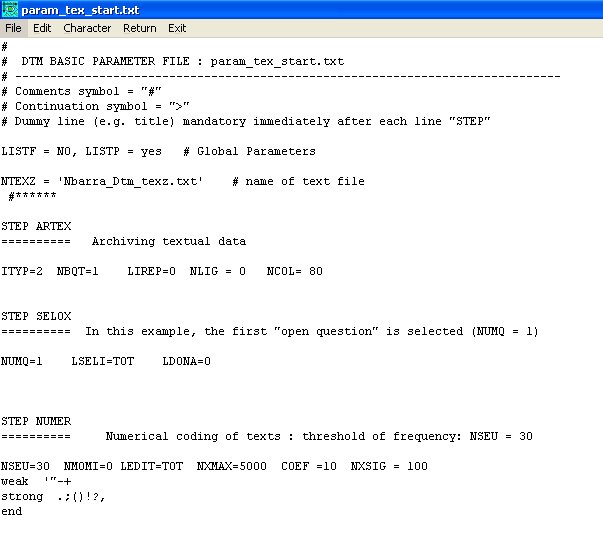
On sauve le fichier modifié (File) et on sort de
l'éditeur (Exit).
On lance alors l'analyse (Execute), qui utilise par défaut le
fichier de paramètres qui vient d'être ajusté.
On voit s'exécuter les différentes étapes.
On peut ensuite examiner les résultats. D'une part les
visualisations via le menu PlaneView en choisissant Active columns :
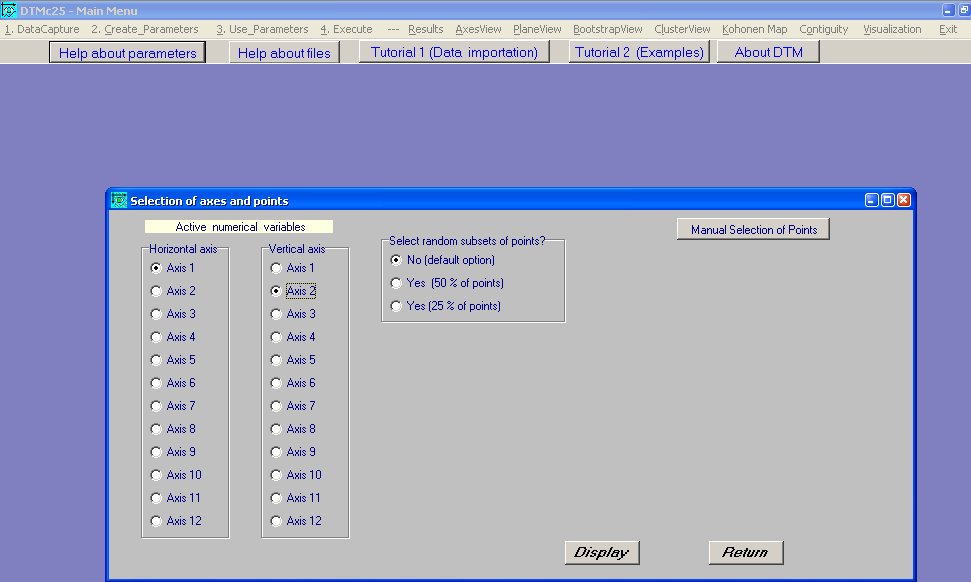
On choisit l'axe 1 horizontal et l'axe 2 vertical pour obtenir les
principales oppositions, puis on clique sur Display.
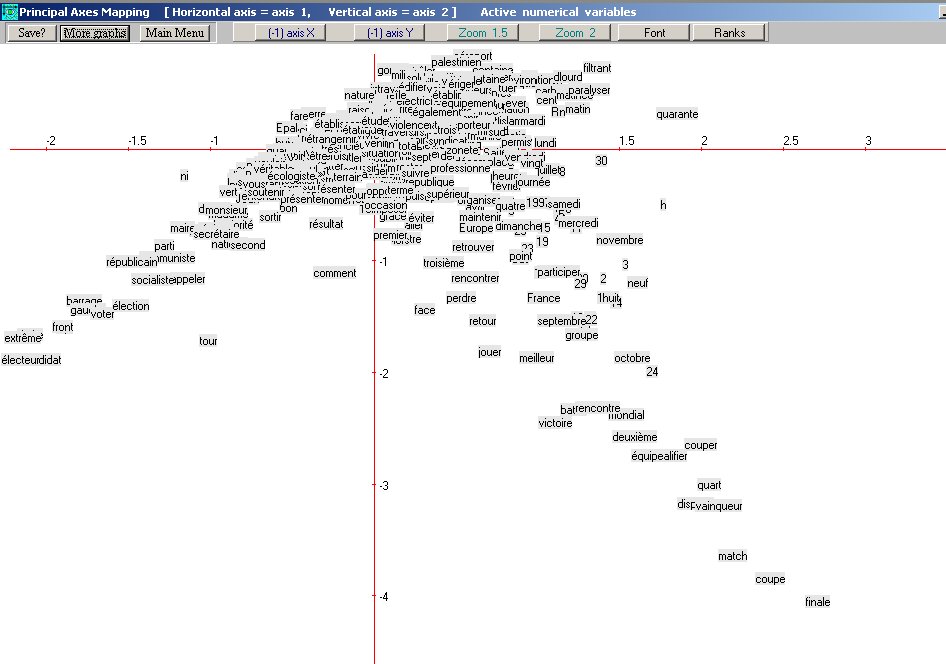
On obtient des visualisations comme ci-dessus (on voit le vocabulaire
politique en bas à gauche, l'emploi sportif en bas à
droite et l'emploi routier ou militaire au milieu).
On peut exporter les images (Save) ou faire des captures
d'écran. Ces visualisations accompagnent utilement les
résultats textuels examinés infra. Dans le
répertoire de travail, on trouve un fichier de résultats
(qu'on peut aussi ouvrir sous DTM avec le menu Results). A la fin, on
trouve le dendrogramme (cf. cours du jeudi) avec les mots
caractéristiques et les textes (phrases
caractéristiques). Ici on voit une occurrence de barrage qui curieusement est
restée. La première classe (appelée en DTM text
number 1) correspond au tir de
barrage ou au mur de barrage
qui peut renvoyer à l'emploi sportif ou à un emploi plus
métaphorique (faire opposition). La deuxième classe est
celle du barrage routier.
Enfin la troisième classe est celle de l'emploi sportif (avec la
lemmatisation fâcheuse de Coupe
Davis en couper Davis).

Mot choisi
Il vous reste à faire de même sur le mot choisi.
Quelques indications :
- DTM attend au maximum 20 000 phrases. Si le fichier fait plus de
20 000 phrases, utiliser un éditeur pour ne prendre qu'un
sous-ensemble légèrement inférieur à 20 000.
- Essayer plusieurs clusterings en choisissant des nombres de
classes attendues différents (par exemple de 3 à 6). Il
faut donc à chaque fois modifier param_tex_start.txt (nombre de
classes attendues) et relancer l'analyse (Exécute). Attention :
un nouveau lancement de DTM écrase le précédent
fichier de résultat (qui s'appelle imp.txt et qui figure dans le
répertoire de travail). Il faut donc sauvegarder un
résultat sous un autre nom avant de changer de
paramétrage et de relancer l'analyse.
- DTM est assorti d'un manuel qui peut vous aider à aller
plus loin (en particulier l'exemple A.4 EXA04.TDA1, p. 24).